Structured Data Pipeline
Objective
The primary objective of this project is to gain practical skills in generating a data pipeline. The deliverables will involve creating a data pipeline with relational data using Azure's Database and Data Factory. I will be using the AdventureWorks data set published by Microsoft. Here's a notebook that contains all CREATE tables and views queries.
Approach
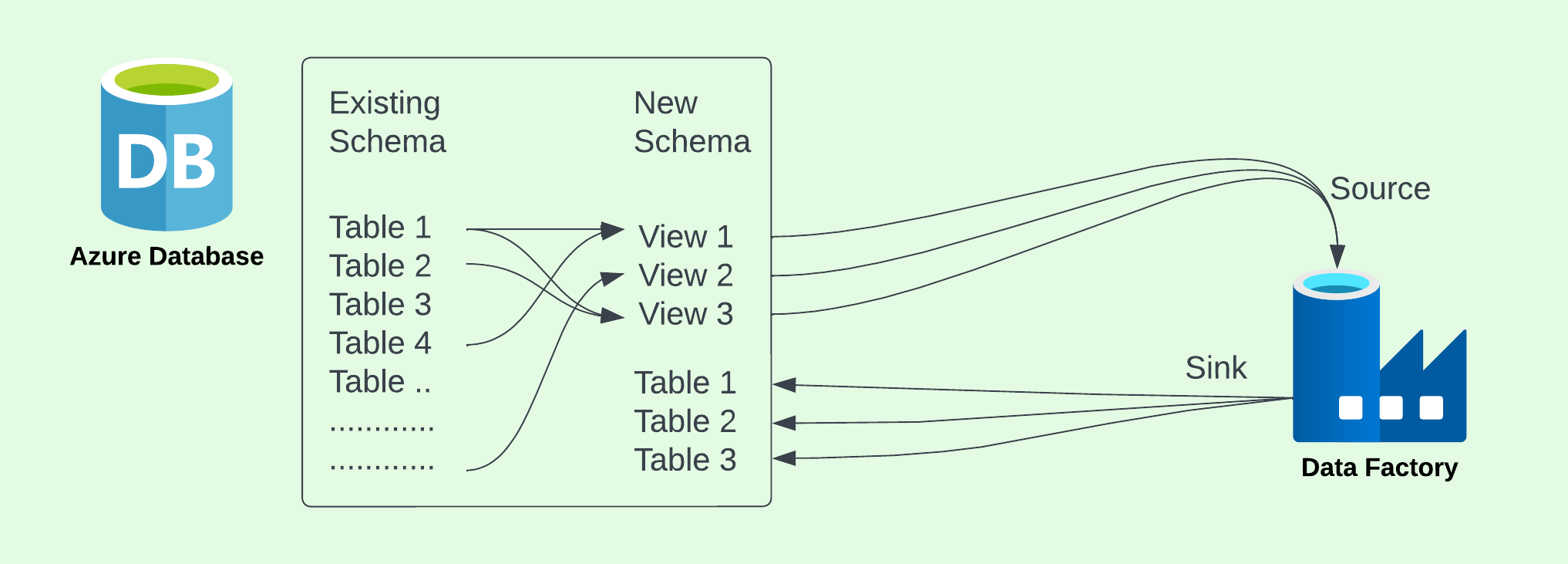
- Step 1: Create a new Schema
- The new schema will have the newly created views and data models.
- Step 2: Create three views
- Three views have been created from the existing tables found under the existing "SalesLT" schema.
- The three views were created using different combinations of the available tables.
- The views will act as the source of the data pipeline.
- Step 3: Create three data models
- Three data models were created in the form of three empty tables.
- The tables will act as the sink of the data pipelines.
- Step 4: Copy data from the views and into the newly modeled tables
- Using Azure Data Factory, the data in the views were copied into thier comparable modeled tables.
- Step 5: Validate that all records were correctly
- A simple SELECT COUNT(*) sql clause applied to each view and its matching table to verfiy that all records were copied.
